


[ad_1]
Paris-based startup Mistral AI, which recently claimed a $2 billion valuation, has released Mixtral, an open large language model (LLM) that it says outperforms OpenAI’s GPT 3.5 in several benchmarks while being much more efficient.
Mistral drew a substantial Series A investment from Andreessen Horowitz (a16z), a venture capital firm renowned for its strategic investments in transformative technology sectors, especially AI. Other tech giants like Nvidia and Salesforce also participated in the funding round.
“Mistral is at the center of a small but passionate developer community growing up around open source AI,” Andreessen Horowitz said in its funding announcement. “Community fine-tuned models now routinely dominate open source leaderboards (and even beat closed source models on some tasks).”
Mixtral uses a technique called sparse mixture of experts (MoE), which Mistral says makes the model more powerful and efficient than its predecessor, Mistral 7b—and even its more powerful competitors.

A Mixture of experts (MoE) is a machine learning technique in which developers train or set up multiple virtual expert models to solve complex problems. Each expert model is trained on a specific topic or field. When prompted with a problem, the model picks a group of experts from a pool of agents, and those experts use their training to decide which output suits their expertise better.
MoE can improve model capacity, efficiency, and accuracy for deep learning models—the secret sauce that sets Mixtral apart from the rest, able to compete against a model trained on 70 billion parameters using a model 10 times smaller.
“Mixtral has 46.7B total parameters but only uses 12.9B parameters per token,” Mistral AI said. “It, therefore, processes input and generates output at the same speed and for the same cost as a 12.9B model.”
“Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference and matches or outperforms GPT 3.5 on most standard benchmarks,” Mistral AI said in an official blog post.
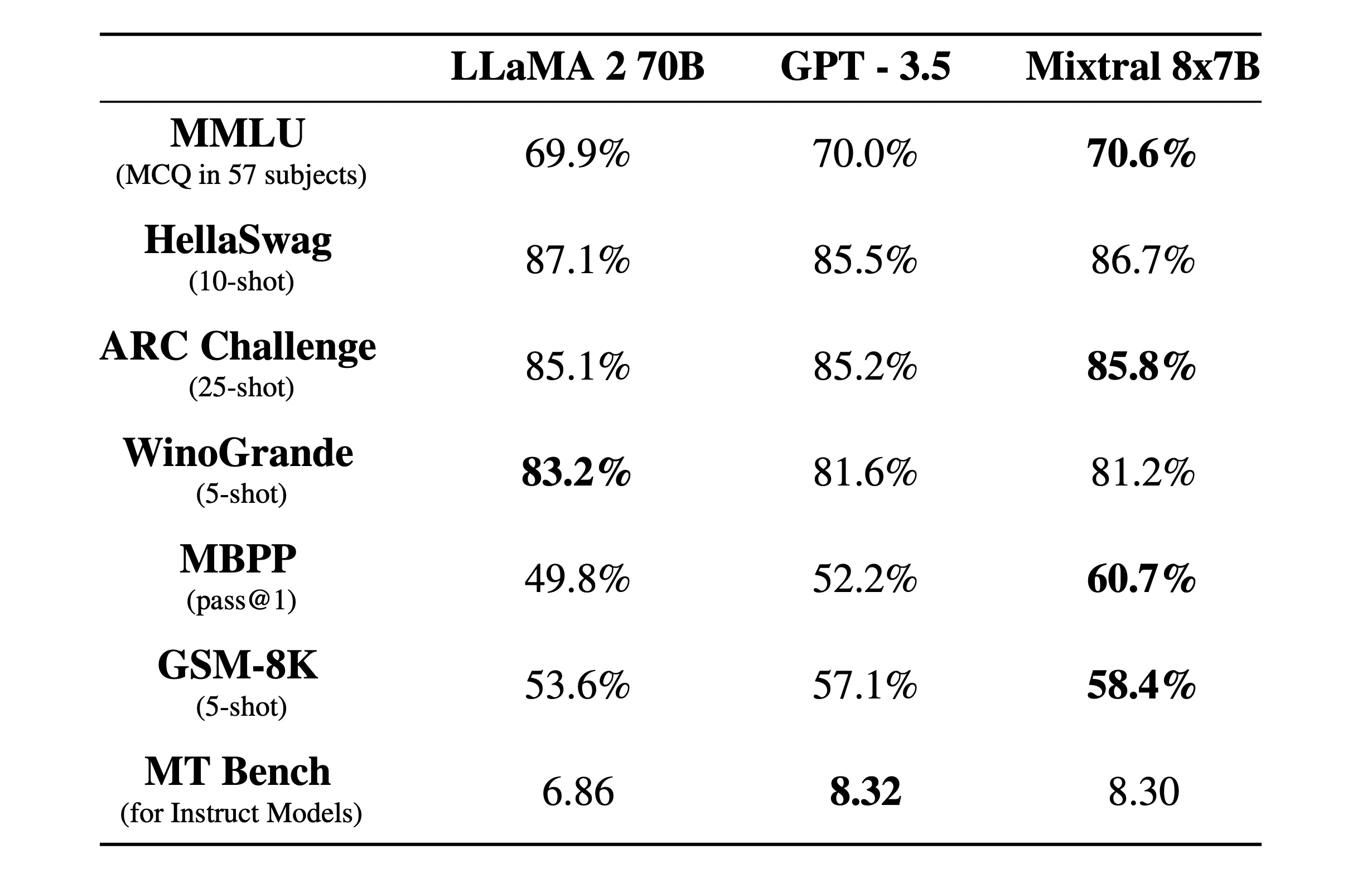
Mixtral is also licensed under the permissive Apache 2.0 license. This allows developers to freely inspect, run, modify and even build custom solutions on top of the model.
There is a debate, however, about whether Mixtral is 100% open source or not, as Mistral says it released only “open weights,” and the core model’s license prevents its use to compete against Mistral AI. The startup has also not provided the training dataset and the code used to create the model, which would be the case in an open-source project.
The company says Mixtral has been fine-tuned to work exceptionally well in foreign languages besides English. “Mixtral 8x7B masters French, German, Spanish, Italian, and English,” scoring high across standardized multilingual benchmarks, Mistral AI said.
An instructed version called Mixtral 8x7B Instruct was also released for careful instruction following, achieving a top score of 8.3 on the MT-Bench benchmark. This makes it the current best open source model on the benchmark.
Mistral’s new model promises a revolutionary sparse mixture-of-experts architecture, good multilingual capabilities, and complete open access, And considering this happened just months after its creation, the open-source community is going through an exciting and interesting era.
Mixtral is available to download via Hugging Face but users can also use the instruct version online.
Edited by Ryan Ozawa.
Stay on top of crypto news, get daily updates in your inbox.
[ad_2]
Source link
